...
...
...
...
...
...
...
...
| Table of Contents |
|---|
Related Jira(s)
...
| Jira Legacy | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
|
| Jira Legacy | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
|
Partial Demo
This demo includes the functional requirements Req. 2 and Req. 6 fully and Req. 4 is partially included.
Assumptions
| Assumption | Notes | |
|---|---|---|
| 1 |
Issues and Decisions
| # | Issue | Notes | Decision |
|---|---|---|---|
| 1 | How fast should CPS (and DB) be able to process max heart beat failures? | is 60K really realistic if ENM goes down we should get a notification for each node do we ?! | PoC has shown 60 seconds is reasonable |
| 2 | Restart of NCMP | Should/Can this be handled? | As of now, there is no such case is being considered. |
| 3 | Does DMI Plugin provide NCMP with a health check URL during registration? Either, just rely on the default one provided with Spring boot actuator? | Document the contract. Its just the interface that matters and not the implementation. | Spring boot actuator interface |
| 4 | Error during cmHandle registration | If an error occurs during registration what trustlevel should the cmHandle be set to? IN eth following scenarios
| Agreed to Leave as is, if notification for a node already registered, we can process the other notification separately Team Notes: [Team] When state was provided to 'COMPLETE' or 'NONE' and the registration fails , state if trust level is still set to the provided state regardless of the current state of the cm handle (deleted/deleting, advise, ready, locked) |
| 5 | Module sync watchdog issues/error scenarios | If cmHandle is set to none/incomplete module sync will automatically retry (Is this acceptable?) If the module sync fails we will still send a Complete message (Is this acceptable?) Registering all cmHandles could take up to 20 mins, what should happen if the last sync fails as the notification would have been sent 20 mins ago? | When CMLevel is in: DELETING/DELETED - No Truslevel notification update ADVISE - No trustLevel notification update READY - Truslevel notification update LOCKED -Truslevel notification update
Team Notes: 12/10/2023 [Team] Notification SHALL only be sent when the Cm handle is set to Ready and locked regardless of the report from DMI Do we still update the cache? Yes. |
| 6 | When cm handle trustLevel state stays the same | Do we include that cm handle ID or not for notifications? | No you don't if no changes if it stays the the same
Team Notes: 12/10/2023 Scenario: DMI plugin up/down the previous state of the cm handle (trsutLevel) should be considered for notifications |
Description
- Define scenarios which cause a CM Handle to go stale.
- Implement changes to support tracking of CM Handle Freshness/Staleness.
What might trigger a cmhandle cmHandle to go to STALE?
- dmi plugin identifies that the device is no longer contactable.
- dmi plugin identifies that an underlying device manager managing the device (node) is out of sync with the device itself.
Requirements
Functional
| # | Interface | Requirement | Additional Information | Sign-off |
|---|---|---|---|---|
| 1 | CPS-NCMP-E-05 | The 'trustlevel' is visible on all REST methods that currently include the 'cm handle state' | existing endpoints |
|
| 2 | CPS-NCMP-E-05 | CM Handles can be queried (filter condition) on 'trustlevel' | using a new 'trustLevel' condition (cannot use cpsPath condition) |
|
| 3 | CPS-NCMP-I-01 | During registration, DMI plugin can report initial trustlevel. If the state is not 'complete', it should be considered as 'Trustlevel change' (See req 5) | Initial trust level will be backward compatible if not set, we assume trustlevel is 'complete' For a new cm-handle where the trustlevel is 'complete' this is NOT considered a chance and no notifications should be sent |
|
| 4 | CPS-NCMP-E-05 | Once DMI (plugin) is detected to be down the trust-level for all affected CM Handles should be set to be 'NONE'. This wil also lead to many notifcations as per req. #5 | this might lead to a high level (20K) of notifications (need to discuss capabilities) |
|
| 5 | CPS-NCMP-E-05.e | NCMP notification shall be sent when the trustlevel changes | Notification be sent externally based on Kafka many small or bulk: Agreed Many notifications, one for each cm-handle |
|
| 6 | CPS-NCMP-I-01.e | It shall be possible to report any trustlevel of one CM Handle DMI plugin can report the current trustLevel of a single cm handle id | i.e. the DMI can tell NCMP the trustLevel is 'NONE' when a node heartbeat failure is detected and 'COMPLETE' once it is restored. Again this should lead to notifications on the external interface as per req #5 |
|
Error Handling
| # | Error Scenario | Expected behavior | Sign-off |
|---|---|---|---|
| 1 |
Capabilities
- re-registration, once a day, same requirement as first time registration
- single node heart beat failures 30,000 / minutes per instances
Scope
...
| NCMP restart (all instances) | To be discussed, not sure if it can/should be handled TrustLevels should be 'NONE' and need to be restored using an audit-request (not in scope) | If we restart, it should go into COMPLETE STATE. No way of getting out of NONE State Audit was agreed to be handled in a separate epic - Prioritise audit epic
Team Notes: 12/10/2023 **If all instances of NCMP restarts [fresh start], there would be nothing in the cache |
Characteristics
| # | Parameter | Expectation | Notes | Sign-off |
|---|---|---|---|---|
| 1 | dmi-down detection speed | 60 seconds | It's a configurable value. Agreed - Should be in parallel with device heartbeat. |
|
| 2 | device heartbeat frequency (message emitted by DMI plugin for each device) | 60 seconds | Can be removed - out of scope for this epic | |
| 3 | maximum supported devices (by NCMP) | 60,0000 | Given #2 and #3 this means NCMP needs to process 60,000 message / minute! - Can be removed, separate epic - out of scope for this epic | |
| 4 | maximum number of cm-handles down report by DMI in one request and/or per minute | 30,000 / minute | a peak can be processed within 60 seconds |
|
| 5 | processing of all trustLevel time for DMI-Down and/or peak load by DMI | 1 second | Agreed to go with 30,000 / minute as no 4 |
|
| 6 | If we incorporate into searches endpoints the speed should not be impacted | 30 seconds | Speed shouldn't be affected - Agreed - It's across 60,0000 cmHandle Open for improvement in respect to performance |
|
Out-of-Scope
...
Assumption is that at CMHandle registration the CMHandle is originally persisted as NONE trustLevel
As CMHandle moves to READY, NONE moves to COMPLETE, Else stays as NONE
The DataSync does not effect this as is related to cache.
...
What Data?
...
What about changes to the CMHandle Properties etc?
...
Schema Model Mismatch
OUT OF SCOPE
Occurs when data change has been called for a CMHandle and the data change does not fit the defined schema for that CMHandle Anchor (passthrough only).
If this error occurs Trust Level is set to NONE.
Open Questions
...
Do we have to store the trust level or can it be calculated when asked?
...
- This epic will only introduce trustLevel NONE and COMPLETE. PARTIAL and POOR may be added later as below.
Changes to DMI Registry Model
We will not be making changes to the DMI Registry Model, Public Properties of the CMHandle will be used where needed.
Triggers of CMHandle trust level change
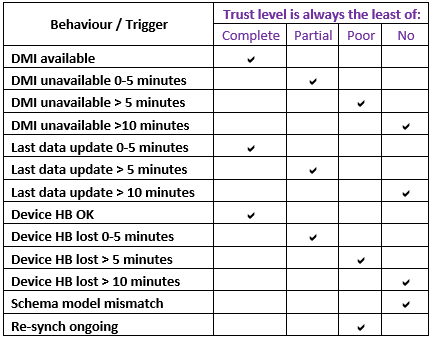
DMI Availability
Ping every 30 seconds configurable or (every communication with DMI OOS)
Health check endpoint already exists
http://'$1'/manage/health/readiness
Hazelcast Map
When DMI comes back up, DMI does audit and provides list of Trustworthy CM Handles
Audit triggered by NCMP with list of CMHandles IDs and for DMI to reregister HTTP
Deltas: DMI handling, properties; Delete all under a DMI? Performance?
...
Device Heart Beat
Assumed functionality is that this will be defined by the DMI Plugin as NCMP does not communicate with device directly
Interface in NCMP for DMI Plugin to be able to tell when device HB has been lost?
10 minute limit should be configurable with 10 as default.
Probably event based
...
DMI-I-01
/health
/v1/ch/trustlevel
{
"Trust":
}
Reregistration
This process occurs when the DMI Plugin Availability is down and then comes back up.
NCMP makes a synchronous call to the DMI Plugin (New Audit Endpoint) to trigger a reregistration
DMI Plugin then reregisters its CMHandles with NCMP (new reregistaration Endpoint?)
NCMP then compares the CMHandles which are being reregistered with the CMHandles which already exist.
CMHandles which are in NCMP but not in DMI reregistration request are kept as trust level none
What happens if there is conflict between the old and new properties of a CMHandle, just take the new properties?
New CMHandles could be registered
Hazelcast for Trust Level
Map Trust level for DMI Plugins
Key: Dmi Name, Values: health check url, trust level
Set Trust level for untrustworthy CMHandles
Key: CmHandleId
When checking the trust level for a CMHandle first check the trust level of that CMHandle's DMI Plugin
If None return None
If Full check trust level for the CMHandle and return that
Last Data Update
OUT OF SCOPE
Trust Level defined by Client's use of NCMP endpoints to change data related to a CMHandle (passthrough only).
10 minute limit should be configurable with 10 as default.
Stored in public properties
...
Open Question: External Notifications NCMP is subscribed to should effect this?
...
- Re-registration i.e. resolving trutsLevel degradation is not in scope of this epic
High Level Interactions
| Drawio | ||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
|
| Interface | Name | Trigger | Description | Type | Endpoint or Topic | Schema |
|---|---|---|---|---|---|---|
| 1 | HealthCheck | 30 second interval (configurable) | NCMP is to perform a health check against each of the DMI Plugins | REST | http://<dmiPluginServiceName>/manage/health This endpoint will be the standard heath check endpoint provided by spring boot actuator. We don't store it anywhere. We just document it for now. | |
| 2 | CMHandle trust level change | A CMHandle managed by DMI Plugin's trust level has changed | data contains {trustLevel: ENUM} event id is cmhandle id in kafka header | Kafka | kafka topic: dmi-device-heartbeat | <cloudEvents-header> id : <cmhandleId> type : org.onap.cm.events.trustlevel-notification data : { |
| 3 | CMHandle Query API with trustLevel Query Condition | Client Request | CmHandle is to be returned based on the values in above CMHandle Trust Map | REST |
| { |
| 4 | Notification on Trust Level Change | NCMP | NCMP sends notification upon trust level changes | Kafka | kafka-topic: cm-events | <cloudEvents-headers> "data": { |
Managing TrustLevel
DMI Plugins
- NCMP is checking every DMI Plugin for health at interface 1 every 30 seconds using the Trust Level DMI Map
- IF a DMI Plugin goes down, that DMI Plugin's health status is updated to NONE in the Trust Level DMI Map
- The CM handles corresponding to DMI should be set to NONE.
- IF a DMI Plugin comes back up, Heath status is set back to COMPLETE for that DMI plugin only.
More details of health check URL can be accessed via:
CPS-1857 Document watchdog job impl. with health check URL
CMHandle Heartbeat
- It is the responsibility of the DMI Plugins to update NCMP about the heartbeat of CMHandle.
- Through interface 2, DMI Plugins will provide a Kafka event on the changing of trustworthiness state of a CMHandle.
- NCMP receives this event and updates the CM Handle Trust Map accordingly
- Needs to be able to handle a throughput of 60,000 State changes per minute for 2 instances
Query CM Handle with Trust Level
Body of request will be in the format as below:
Code Block language text title Search Trust Level Request Body { "cmHandleQueryParameters": [ { "conditionName": "cmHandleWithTrustLevel", "conditionParameters": [ {"trustLevel": "COMPLETE"} ] } ] }
There are two end points will be subject to query:
http://<host>:<port>/ncmp/v1/ch/id-searches
http://<host>:<port>/v1/ch/searches- Interface 3
- NCMP will first check trust level query parameters to determine which trust level (NONE, COMPLETE) is being searched.
- Then, the trust level for both DMI and CM Handle should be compared, and minimum of two (effective trust level)
must be selected. - If the target trust level (comes from the request) is equal to effective trust level (obtained in step a.),
then cm handle should be included in the response.
- Then, the trust level for both DMI and CM Handle should be compared, and minimum of two (effective trust level)
Notifications on Trust Level Changes
NCMP will send timely notifications in case of any alterations in a device's trust level via Kafka interface.
Proposal for Notification's Schema
kafka-key : cmHandleId ( *Note : when publishing the notification , use the cmHandleId as the key of the message. This will enable clients to read the most updated message/state when the compaction is triggered)
Cloud event Definition
Element | Name | Parent | Type | Mandatory | Description | Format | (example) Value | |
|---|---|---|---|---|---|---|---|---|
| 1 | Header | id | String | Yes | random id for cloud event header. UUID is suggested | |||
| 2 | source | String | Yes | source of information | ncmp.<cmhandle-id> | ncmp.12ac34e43556e | ||
| 3 | specversion | String | Yes | cloud event version spec | fixed value | 1.0 | ||
| 4 | type | String | Yes | type of event | fixed value | trustLevelChangeEvent | ||
| 5 | dataschema | String | Yes | data schema | fixed value | org.onap.cps.ncmp.events.cmhandle.TrustLevelChangeEvent:1.0.0 | ||
| 6 | correlationid | String | Yes | The cmHandle which is been notified. The value will be similar as we have in the source field. | <cmhandle-id> | |||
| 7 | Payload | data | Object | Yes | The actual data payload. Details will be provided below. | 3GPP TS 28.532 standard | ||
| 8 | attributeName | data | String | Yes | The attribute which has changed. | <name> | trustLevel | |
| 9 | oldAttributeValue | data | String | No | The old value of the attribute which has changed. | COMPLETE | ||
| 10 | newAttributeValue | data | String | No | The new value of the attribute which has changed. | NONE |